




Tiens je vais te raconter un truc rigolo de gros noob du cul qui pense pouvoir la faire à des vieux de la vieille. Spoiler, le noob, c’est moi. Les vieux de la vieille, ce sont les devs de Reddit.
La naïveté de mon approche va probablement faire rire quelques barbus.
Pour un de mes sides projects, j’ai besoin d’accumuler beaucoup de data sur Reddit. En gros, j’ai besoin de pouvoir couvrir des semaines d’activité d’un sub que je choisi. Et pour certains subs, ça veut dire rapatrier des MILLIERS de posts voire des dizaines de milliers.
Problème : depuis mars et leur enquête interne sur les bots qui tentent d’influencer le peuple lors d’élections, Reddit a drastiquement limité son API. Justement pour éviter que le site ne contribue à d’autres manipulations d’élections. Fuck. Enfin, non, c’est bien mais là c’est vraiment relou pour moi.
Donc maintenant, l’API de Reddit, te permet de rapatrier 1000 posts d’un sub. Pas plus. Tu ne peux pas remonter dans le temps indéfiniment. Un peu tristoune le Klaki.
Du coup je cherche une solution pour remonter quand même plus loin.
Ce que je sais à ce moment là :
- Quand tu surfes sur Reddit, que tu vas dans l’onglet ”nouveaux” d’un sub, tu as les 25 derniers posts, et un bouton ”suivant”.
- En cliquant sur ”suivant”, tu as les 25 posts suivants et ainsi de suite.
- L’API me permet tout de même de récupérer toutes les infos d’un post si je lui fournis l’identifiant unique du post en question. Peu importe son âge. Cet identifiant à pour forme ”t3_azerty” ou ”azerty” (”t3” servant en fait à spécifier le type de contenu, en vrai on s’en fout)
- Cet identifiant unique de chaque post, il est dans le code source de la page web listant les posts d’un sub.
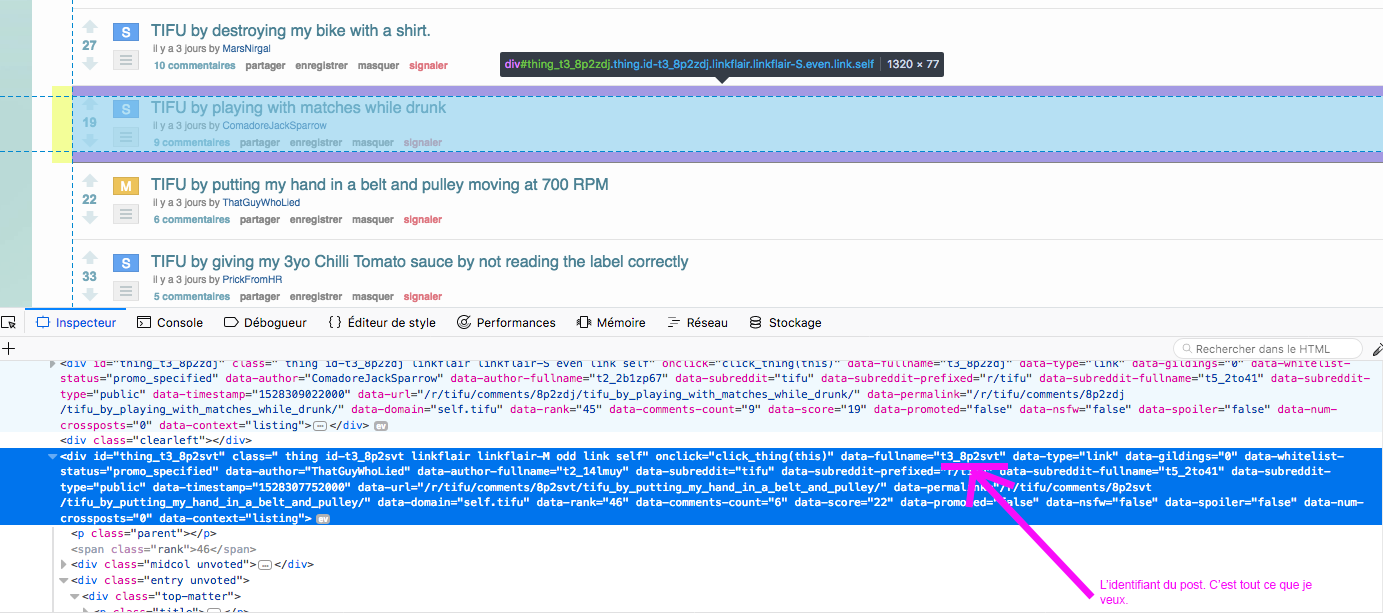
Dans un éclair de génie, je me dis que je pourrais donc faire parcourir à un script TOUTES les pages de l’onglet ”nouveaux” du sub pour récupérer les ids uniques des posts les uns après les autres.
Là les vrais devs doivent commencer à avoir un sourire en coin en voyant le petit rossignol chantant que je suis foncer à mach 5 vers le mur des désillusions.
Si tu sais pas ce qu’est un scraper, pour ce qui nous concerne ici c’est robot qui ouvre un navigateur et réalise des actions scriptées. Il navigue là où tu as besoin, il analyse le code source, prends les infos que tu lui demandes de prendre, clique sur ”Page suivante”, et recommence. Il fait ce que tu mettrais des plombes à faire toi même et transmet ce qu’il trouve à ton script qui va ensuite l’exploiter. Tout ça sans avoir recours à une API et ses limitations.
C’est pas mon premier. J’en avais déjà fait un pour mon enquête sur les concours faisant gagner des comptes premiums. À l’époque, ce scraper me servait à construire un catalogue de tweets tout prêts pour se faire passer pour un humain. On était sur une échelle beaucoup plus petite de collecte.
Je passe 6 heures hier en terrasse à faire ça. Et j’essaye surtout de le faire le plus efficace possible. Parce que je cherche à obtenir une quantité de data assez conséquente et que j’aimerais bien que ça prenne pas 50 ans. Donc je me fais chier, vraiment, à tester et re-tester le truc sur 250-500 posts, et je chronomètre pour gratter le plus de temps possible à chaque fois. Rien de ouf pour les vrais devs, mais j’en suis encore au stade ou passer de 5 ids/seconde à 15 ids/seconde, me fait me sentir fort 🙂 .
C’est pas mon métier hein, j’essaye juste d’apprendre en m’amusant.
Bon du coup me v’la avec un truc qui trace et qui sans dépendre de l’API et de ses limitations, peut me faire récupérer 1000 posts à la minute. 60000 posts à l’heure, ça me va. T’façon je peux pas faire autrement.
Je lance sur un sub, au hasard /r/France, et je demande la récupération de 10000 posts. On va voir ce qu’on va voir mon p’tit bonhomme !
Tout se déroule à merveille. Quand soudain :
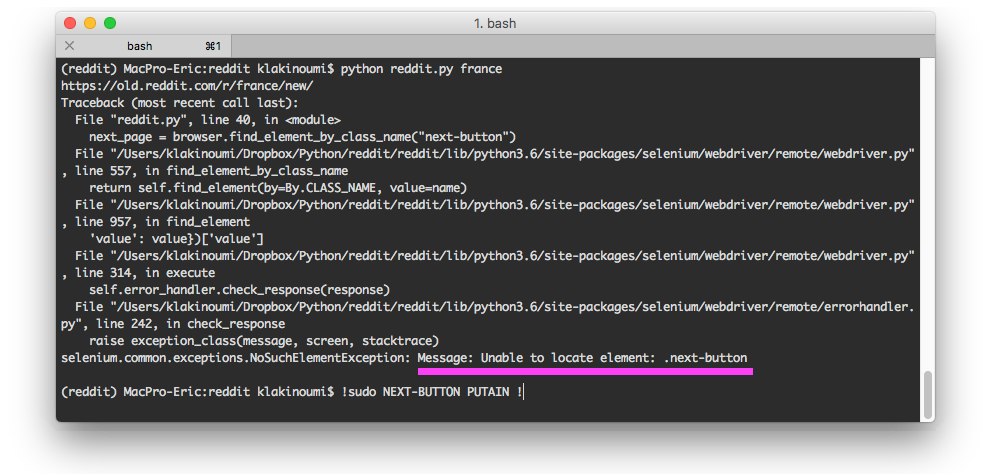
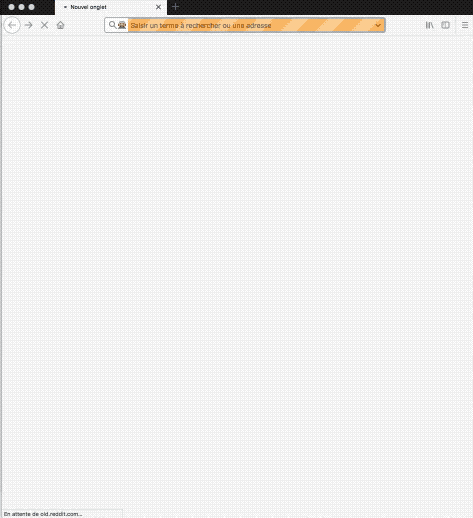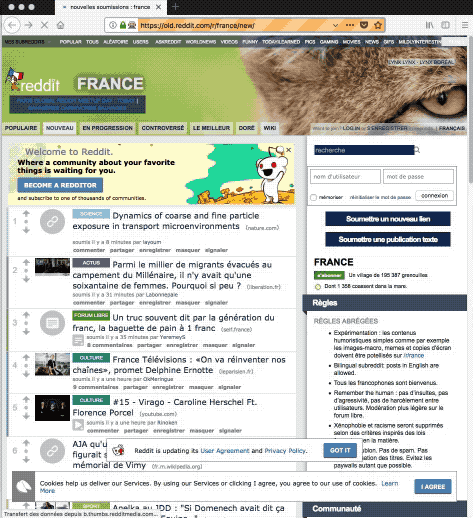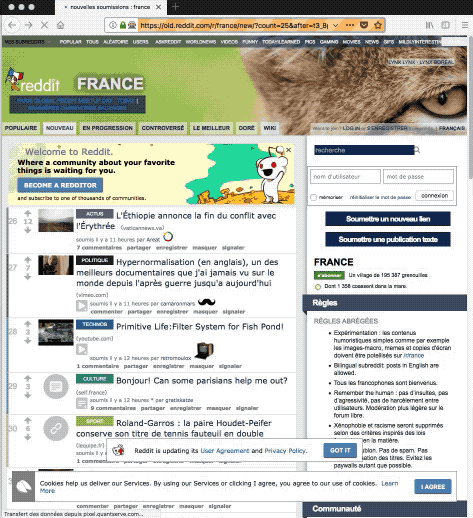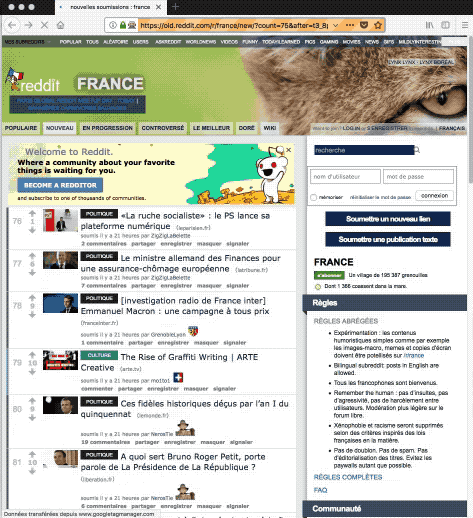
”Bah ! Pourquoi qu’il trouve plus le bouton page suivante d’un seul coup ce con ?” me dis-je plein de certitudes ne demandant qu’à se transformer en rêves brisés.
Je vais donc sur la page où le script ne trouve pas le bouton lui permettant de continuer à récupérer mes ids de posts.
Et là, c’est le drame :
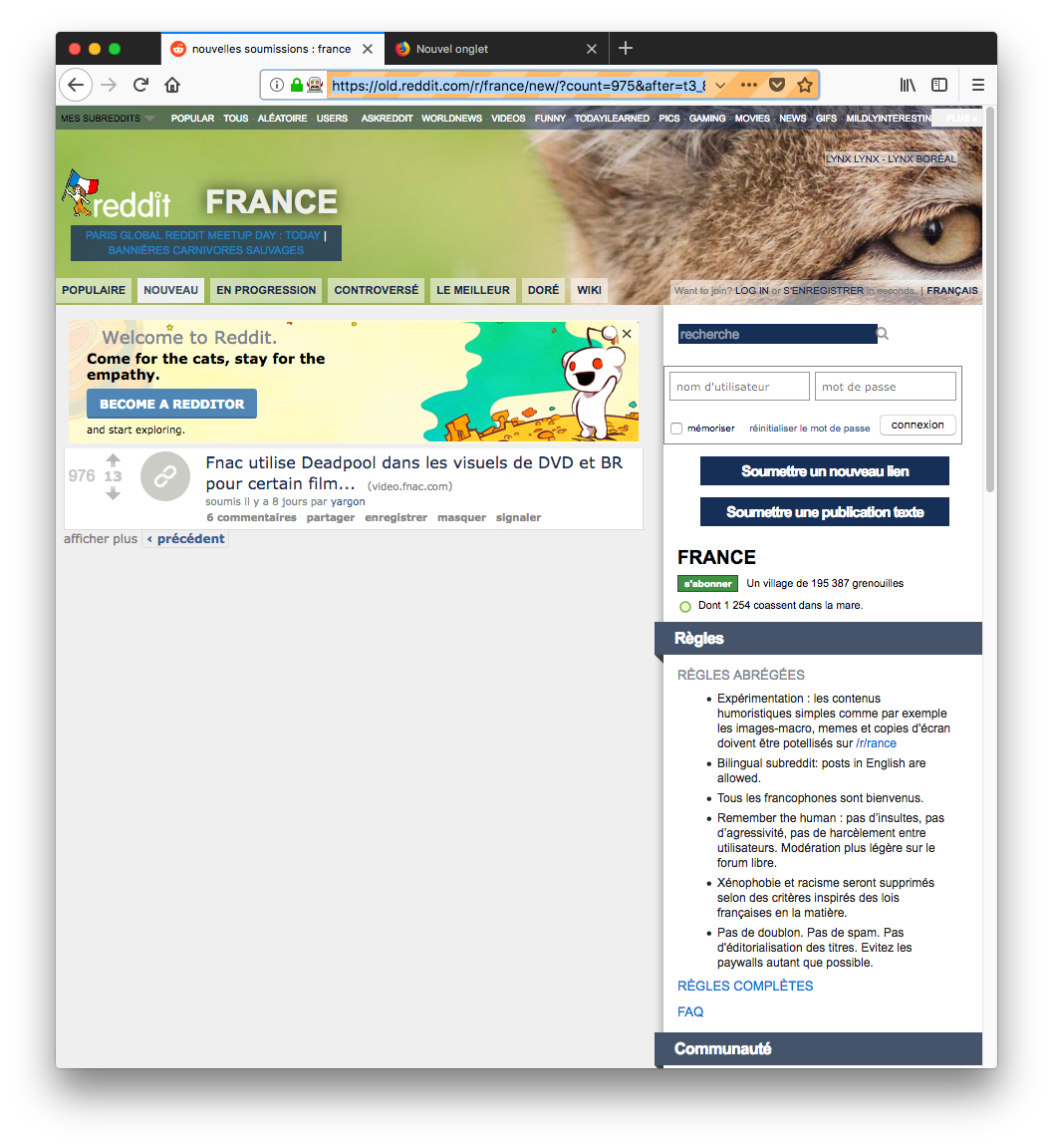
A pu bouton !
Eh oui Jamy ! Si ton script ne le voit pas, c’est qu’il n’y a pas de bouton ! Et si il n’y a pas de bouton, c’est parce que les mecs de Reddit ne sont pas cons. Ils ne vont pas te laisser faire via le web ce qu’ils t’empêchent de faire via l’API.
J’ai essayé de crafter l’URL pour aller plus loin, mais rien n’y fait. Enfer et damnation, je suis fait !
Alors qu’avons-nous difficilement appris aujourd’hui ?
- Les limitations d’API c’est le premier truc à creuser avant de commencer à dev un script qui les utilise.
- Que si tu penses contourner les limitations d’une API par d’autres moyens, il faut tester une preuve de concept avant de passer 6 heures à faire un truc qui fonctionne SUPAYR mais qui FAY PAS MIEUX !
- Que le développement ça renforce l’humilité.
- Avec le recul, je me sens TELLEMENT CON d’avoir pensé que ça fonctionnerait.
Mais quand j’ai compris à quel point j’ai été naïf de croire que j’allais m’en sortir comme ça, j’ai éclaté de rire. ”Mon pauv’drôle… T’es vraiment tout neuf dans ce domaine…”
Voilà, c’est tout pour cette fois, à bientôt pour vous raconter mon prochain fail de script kiddie 🙂
Et ça devrait pas tarder parce que j’explore une autre méthode pour obtenir le même résultat (enfin, une version qui fonctionne) et que je sens déjà que je vais me faire lourder 😀 . Accessoirement, si quelqu’un à une piste… Promis, c’est pas pour faire des bêtises.








Salut,
D’abord sache qu’il n’y a rien de ridicule à avoir tenté la solution du scrapper. 9 fois sur 10 ça fonctionne parfaitement !
Après tu as des solutions pour réussir quand-même avec un scrapper.
Voici quelques éléments à essayer :
– définir des en-têtes qui te font ressembler à un utilisateur (user agent de navigateur, langue acceptée, etc.)
– faire des poses régulièrement mais de façon irrégulière (càd que tu fais par exemple une pause de 10 secondes puis tu scrappes, puis tu pause 1 seconde et scrappes, puis tu pause 24 secondes, etc.).
– récupérer les identifiants et les messages de façon asynchrone. Càd que tu scrappes avec un script qui va mettre les identifiants dans une file d’attente dans laquelle un autre script va piocher un élément régulièrement.
Si tout ca ne fonctionne toujours pas, il te reste une solution, la répartition sur iOS différentes.
Concrètement tu vas utiliser disons une dizaines de machines différentes, et au lieu de faire directement la requête depuis ta machine tu va demander à une machine aléatoirement de récupérer 3 pages, puis attendre quelques secondes et demander à une autre machine d’en récupérer 3 autres, etc.
Tu peux aussi faire ça toujours depuis ta machine mais en changeant ton ip aléatoirement avec un vpn (tu peux jeter un œil ici pour voir comment se connecter à un vpn sur une machine linux https://raspbian-france.fr/connectez-raspberry-pi-vpn/).
Après il te reste encore d’autres solutions plus compliquées qui peuvent parfois être essayées pour contourner des limites de consultation, comme ouvrir beaucoup de requêtes http vers des pages en les laissant ouvertes mais vides jusqu’à saturation puis envoyer tu le contenu le plus vite possible pour récupérer un max de données avant d’être bannis, puis recommencer avec une autre ip. Mais ça marche mieux pour attaquer un service que pour récupérer des données.
Note que si ton parser nécessite d’être connecté au préalable tu as intérêt et utiliser plusieurs comptes aléatoirement.
Enfin, il te reste une dernière solution, toute simple : tu fais un petit tweet au support de Reddit ou à leur compte développeur si il existe pour leur expliquer ton projet et leur demander s’ils peuvent faire une petite exception pour toi ! Tu peux faire pareil directement au prêt d’un dev chez Redditd en lui demandant s’il peut t’aider à obtenir une petite dérogation, les boîtes ont parfois des API internes illimitées et un dev pourrais avoir le droit de s’en servir pour ses projets perso.
Voilà, j’espère que ça pourra t’aider !
Sinon, bravo pour ton article sur les concours twitter ! J’aimerais bien te poser une question sur le sujet, il y aurait moyen que tu m’envoies un tweet à @raspbianfrance ?
Il est possible d’afficher 100 posts au lieu de 25 en rajoutant le paramètre « limit » dans l’url tu aurais pu gagner d’autres précieuses seconds 😉
@raspberry pi : peu importe la manière de scrapper de randomiser les users agents etc. puisque là même en web, reddit limite à 1000 posts maximum pour un sub donc ça ne sert à rien.